
What can a Computational Approach bring to Social Care Research?
By Charles Rahal and Daniel Valdenegro-Ibarra
The regular ‘Care Data and Methods’ seminars held by the Centre for Care do a wonderful job of showcasing the plurality of methods used across and beyond all of the different research groups and teams. From Prof. Gwilym Pryce’s opening of the series on the subject of causal methods, through to the recent seminar which focused on arts-based methods as data collection, it is apparent that a healthy and diverse range of methods are currently being utilised across the Centre. However, much more remains to be done with regards to the potentially fruitful integration, and indeed development of computational methods. Daniel Valdenegro Ibarra and Charles Rahal outline what is being done at the Centre for Care in this area with the specific objective of reducing inequalities across the social care landscape.
Research in Social Care in the UK has historically been dominated by qualitative methods. While this statement may be controversial, it would be less controversial to say that participatory and ethnographic methodologies enjoy more popularity and visibility than, for example, studies using ‘big’ administrative data or artificial intelligence. Qualitative methodologies are especially well suited to answer questions regarding life events and trajectories of individuals in great depth. That being the case, you may ask: Why should we care about adding new methodologies if the current ones are perfectly adequate? We will try to convince you that we shouldn’t only be interested in the research questions that we already have, but also about new questions which can be answered with new, complementary methodologies as part of a mixed-methods toolbox. And in that regard, we believe that computational methods have enormous potential.
It is important to highlight that not all quantitative research is necessarily computational in nature. In general, computational research distinguishes itself from regular quantitative methods in its intensive use of computational resources. Although regular statistical methods do most often use a computer program to perform calculations, the computer itself it’s not an essential part of the process, as one can argue the calculations could be performed even without it. Computational methods, on the other hand, leverage and depend on computers to provide answers to research questions that might be too difficult or infeasible for us to do manually. Such problems might include large simulations, the analysis of very large datasets, or other mathematically intensive operations. We note that research in Social Care has not historically ventured too far into computational territories, although there is an existing body of simulation work. That is not to ignore the plethora of excellent quantitative work which has been done, not least by many members of the Centre and its national and international partners. However, these works tend to use more traditional statistical techniques and do not make use of the advances which researchers currently enjoy with regards to recent increases in the availability of computational power, both in terms of local personal computers and via high performance or cloud computing. Our field has been somewhat slower than its social science compatriots in adopting – for example – applications of machine learning (Rahal, Verhagen and Kirk, 2022).
Second, not all computational methods deliver what we usually imagine to be “quantitative results”. A very reasonable critique to traditional quantitative methods is that they, indeed, quantise a world that we perceive as continuous and often difficult to measure. Complexity reduction is, after all, one of the goals of many quantitative techniques, especially considering the limitation of computers themselves. But as we push hardware limitations further, the outcomes of the models can become less constrained and start to resemble the complexity of the original problems. Such is the case, for example, with recent advances in Large Language Models (e.g. GPT4) which are able to simulate understanding of a language to previously unthinkable levels. However, this is not to conflate computational methods with black boxes, or a lack of theory. Interpretable machine learning algorithms are rapidly developing, and the use of social theory is likely as relevant as ever.
This idea of computationally addressing multidimensionality is one of our main motivators to explore complex social problems using computational methods. These methodologies open avenues to explore new research questions. This question need not be tied to new forms of data. Computational methods allow us to revisit existing sources of data and questions, expanding upon them with recent developments in our analytical toolbox. Our hope is to capture more of the complexity of the real world by providing our models with more degrees of freedom to examine the distribution of feasible outcome spaces.
How do we foster the emergence of research questions using computational methods? We believe there are four conditions required for them to flourish:
- Sufficiently rich datasets (observational or generative) which contain complex patterns and information.
- Algorithms capable of detecting such complex patterns and information.
- Computational resources which can deploy algorithms at scale.
- Training for researchers able and willing to use such techniques.
We believe these conditions are currently being met in the broader area of social care research, and that there is now a vast array of advancements which can be made via computational approaches. We outline the specific avenues which we think are most fruitful, and those which we are advancing in our pursuit of enriching the social care evidence base within the Centre for Care.
One of the primary concerns of all observational empirical work in general is that of ‘researcher degrees of freedom’. That is; how does each individual choice which a researcher makes affect the resultant outputs? In a more classically quantitative, regression-based paradigm, this generally relates to ‘specification curve’ analysis (first proposed by Simonsohn et al, 2020); a revolutionary technique which jointly considers all possible choices made by a researcher pertaining to how they could have specified their regression models. We believe this idea is relevant to the area of social care, where research can have a very direct and immediate impact on policies which affect the quality of life for a large number of individuals. Given this, rigorous robustness checks of past and future quantitative estimates findings are necessary. We are advancing the specification curve literature and landscape for use within and beyond the Social Care landscape, enhancing many of the functionalities of typical specification curve code libraries. This includes, for example, the integration of tools which allow us to both ‘select’ and ‘average’ across the best of all theoretically reasonable models which a researcher might have been able to choose. See Figure 1 (below) from a current work in progress (just accepted for presentation at a leading conference in our field), which showcases this tool. Specifically, it replicates and re-analyses the seminal social care work of Zhang, Bennett and Yeandle (2021, BMJ Open), which considers the effect of local government spending on adult social care and carers’ subjective well-being in England. The interpretation of the β coefficients is that where local government spending on adult social care is low, the subjective well-being of carers is β points lower on the GHQ-12 scale in comparison to noncarers.
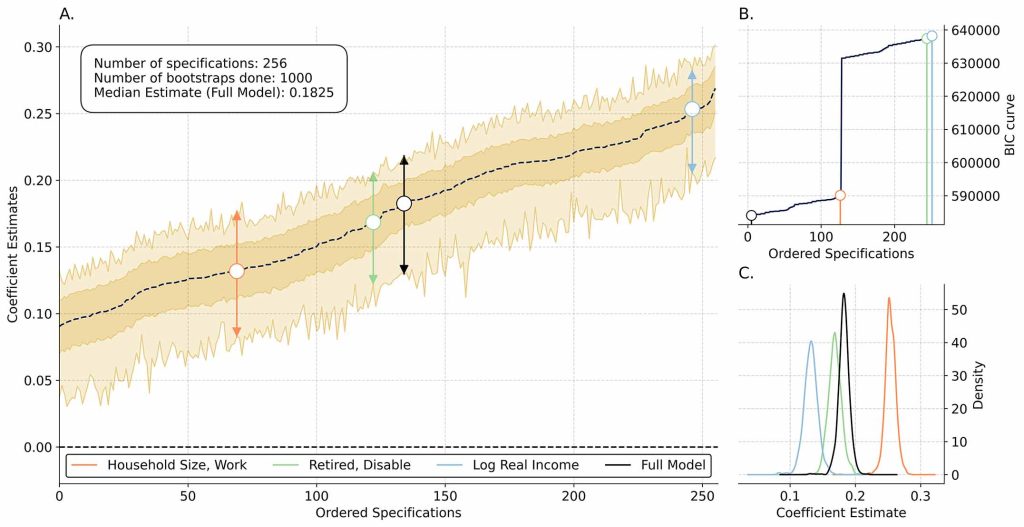
As expected, the original results of the paper (β = 0.1893) appear in the centre of the curve, and all their feasible results are statistically significantly different from zero: we can conclude that their work is in general extraordinarily robust! All of our work in this area involves making use of the replication packages of existing published papers, and allows a thorough re-examination of the scientific record. All of the software packages which we are producing are free, open source and publicly available (such as [here], for example) and can be used to ensure the robustness of the scientific record both within and beyond the field of Social Care research.
Other work which we are in the process of completing involves a computational expansion to the (causal) Individual Synthetic Control based method of Vagni and Breen (2021). The idea of this approach is simple: create a ‘counterfactual’ version of a person based on weights of all of those most similar to them in a dataset, and then use this person (or other unit of analysis) as a ‘control‘ version of what would have happened had they not experienced some ‘treatment’. We can use this – in conjunction with our extensions to this method – to answer questions such as: What would have happened if somebody had not provided social care to another (or had not received it when needed)? How do these effects aggregate up from the micro, to the meso or macro levels? How are these effects stratified across age, ethnicity, gender, or geospatial location? This approach is especially useful for the evaluation of specific government policies, and all of this can be done with existing large longitudinal datasets: something which the United Kingdom has in abundance.
A third project which we are working on is part of a broader narrative surrounding (health-)care more generally, and that relates to the use of ‘artificial intelligence’ and ‘machine learning’. There have been a large number of commentaries in recent years which have promised an ‘AI Revolution’ in (health-)care (such as Davenport and Kalakota, 2019), but few notable exceptions truly revolutionize any particular clinical problem (with the exception, perhaps, of AlphaFold2 as described in Jumper et al., 2021). Working with Dr. Kate Hamblin – a world leading expert in the field of technology assisted care – who leads the ‘Digital Care: roles, risks, realities and rewards’ theme at the Centre and in combination with public sector data providers (primarily in the form of city councils), we are beginning to utilise granular and detailed information about people who may be in need and receipt of care. This data most often comes from ‘wearable devices’ which create ‘alarms’ or ‘alerts’ and is typically used to identify when people may require urgent or non-urgent assistance. Under a ‘predict and prevent’ framework, we aim to integrate ‘deep learning’ based technologies for the first time, aiming to provide tools which predict exactly who will need care – and when – in the form of an ‘early warning system’. A specific application, for example, would be to predict when ‘falls’ occur. While sensitively treating patient confidentiality and ensuring rights to privacy, we believe that this important, predictive work will be able to better prepare emergency response providers, and in the process substantially improve the experiences of both those who require and provide social care.
We’ve outlined three of the exciting things that we’re working on in the areas of observational, causal, and predictive computational social science all with frontier applications to social care research. They each involve a different source of data: replication files, large longitudinal surveys, and bespoke, proprietary data. All of this is built on a solid foundation of open-source code and free, open-source software (FOSS), and has hopefully given an insight into what computational social science makes possible in the field of social care research. However, computational social science of this form is, indeed, still in its infancy and not without various challenges pertaining to things such as data access. Nor is it a panacea; computational approaches are in no way designed to replace or substitute for qualitative, or indeed quantitative approaches. Indeed, progress is often made when we pair multiple approaches together to gain maximal insight, as many members of the Centre are currently doing.
In our next blog post entry in this series in a few months time, we will detail our early progress on building a public facing simulation which exactly replicates the social care landscape, and provides a tool which enables the analysis of various competing policy responses across the care ecosystem. See you then!
References
Davenport, T. and Kalakota, R., 2019. The potential for artificial intelligence in healthcare. Future healthcare journal, 6(2), p.94.
Jumper, J., Evans, R., Pritzel, A., Green, T., Figurnov, M., Ronneberger, O., Tunyasuvunakool, K., Bates, R., Žídek, A., Potapenko, A. and Bridgland, A., 2021. Highly accurate protein structure prediction with AlphaFold. Nature, 596(7873), pp.583-589.
Rahal, C., Verhagen, M.D. and Kirk, D., 2021. Machine Learning in the Social Sciences: Amara’s Law and an inclination across Foster’s S-Curve. SocArXiv. doi, 10, p.31235.
Simonsohn, U., Simmons, J.P. and Nelson, L.D., 2020. Specification curve analysis. Nature Human Behaviour, 4(11), pp.1208-1214.
Vagni, G. and Breen, R., 2021. Earnings and income penalties for motherhood: estimates for British women using the individual synthetic control method. European Sociological Review, 37(5), pp.834-848.
Zhang, Y., Bennett, M.R. and Yeandle, S., 2021. Longitudinal analysis of local government spending on adult social care and carers’ subjective well-being in England. BMJ open, 11(12), p.e049652.

Charlie is a Senior Departmental Research Lecturer and member of the senior management team at the Leverhulme Centre for Demographic Science, a Co-Investigator at the ESRC Centre for Care, and a steering group representative at Reproducible Research Oxford.

Daniel works with Charlie in the Centre for Care team based in oxford studying Inequalities in Care.
More commentary

Becky Driscoll provides an overview of our most recent policy breakfast event in Westminster, where our attendees heard from our researchers and contributed to a discussion on how the Department for Work and Pensions can re-build a meaningful releationship with carers.
Read More about How can the Department for Work and Pensions re-build trust with carers? Highlights from our policy breakfastJohn Perryman and Kate Hamblin explore the case for paid carers leave as the Department for Business and Trade seeks views on the leave options available to unpaid carers.
Read More about The Case for Paid Carer’s Leave
Duncan Fisher writes about his recent trip to visit long-term Centre for Care and CIRCLE collaborators in Finland, made possible by our Capacity-building fund.
Read More about Progressing our international relationships in Finland
As we recognise Co-production Week 2026, the imperative to reshape how social care is understood, researched, and delivered has never been more urgent. At the Centre for Care, co-production is not an add-on or a checkbox exercise for our research teams; it is our foundational methodology. By elevating lived experience to the status of expert […]
Read More about Co-production in Action: Redefining Value, Power, and Knowledge in Social Care Research